
在几次旅途中,我试图将新拍的照片上传到长沙家中的 Immich 服务器。过去我用 Cloudflare Tunnel 做反代,但由于国内特殊的网络环境,连接慢速、频繁中断、上传失败几乎成了常态。后来我开始尝试 Tailscale —— 一个基于 WireGuard 的内网穿透工具,它终于让我在全国各地都能稳定、高速地访问家中的 NAS 和照片库。
但新的问题也随之而来:Tailscale 在 Android 手机上运行时,需要作为 VPN 服务接管系统流量,而我平时使用的 Clash 同样依赖 VPN 接口进行分流。由于 Android 系统限制(只能启用一个 VPN 服务),两者无法共存,导致我必须在「访问家中服务」和「科学上网」之间二选一。
这篇文章从 Tailscale 的原理讲起,到自建 DERP 服务器优化连接质量,再到如何用 iptables 劫持 Tailscale Exit Node 的流量并转发给 ShellCrash,实现流量的灵活转发与安全穿透。无论你是想访问家庭局域网上的 NAS、照片库,还是希望在陌生网络中保护自己的数据安全,这篇文章都能为你提供一套实用、稳定的解决方案。
什么是 Tailscale
Tailscale 是一款基于 WireGuard 协议的零配置虚拟局域网工具,它能够让分布在不同网络环境中的设备像处于同一个安全内网中一样互联互通。通过自动穿透 NAT、防火墙等网络障碍,Tailscale 让你无需公网 IP、无需端口转发,也能轻松访问家中的 NAS、个人服务器、开发环境等内网资源。它的核心优势在于简单、安全、稳定,启动即用,数据传输全程加密,适合个人开发者、远程办公者、家庭用户等多种场景使用。
Tailscale 的技术实现非常巧妙:其构建在 WireGuard 加密协议之上,却颠覆了传统 VPN 的 IP 分配逻辑。每个设备通过 SSO/OAuth2 完成身份认证后,会获得一个终身绑定的节点密钥。这种基于身份的组网模式,让「长沙的 NAS」和「香港的手机」在虚拟网络中如同办公室同事般直接对话。
Tailscale 的连接过程原理
中心控制服务器(Control Server)
每个 Tailscale 客户端在启动后,首先会连接控制服务器(controlplane),进行身份验证,并拉取整个网络中其他节点的信息,包括每台设备的公网 IP、端口、NAT 类型等。这一步相当于是「认识朋友」。
Tailscale 的控制服务器不会转发任何数据,只负责协调连接 —— 类似一个调度中心。
DERP 服务器
说到 Tailscale 能保持高连接成功率的关键,就不得不提到 Tailscale 自研的中转协议 DERP,在 Tailscale 的网络架构里,DERP(Designated Encrypted Relay for Packets)是一个很重要但通常只在必要时介入的组件。简单来说,它就是一个基于 HTTP 的加密中继服务器,用来在两台设备无法直接通信时,作为它们之间的「中转站」。
所有客户端之间的连接都是先选择 DERP 模式(中继模式),这意味着连接立即就能建立,用户无需等待。然后连接双方开始并行地进行路径发现,通常几秒钟之后,Tailscale 就能发现一条更优路径,然后将现有连接透明升级(upgrade)过去,变成点对点连接(直连)。1
需要注意的是:
- 所有通过 DERP 的数据都是端到端加密的,DERP 服务器无法查看内容;
- Tailscale 会尽可能少地使用 DERP,一旦直连建立成功,就会自动切换过去;
- 官方部署了多个分布式 DERP 节点,客户端会自动选择延迟最低的那个;
- 你也可以自建 DERP 节点(比如在国内),来解决延迟高或连接不稳定的问题。
可以把 DERP 理解为一个兜底机制,虽然性能不如直连,但确保了即便不能打洞成功,设备之间也始终能保持连接。
NAT 穿透(NAT Traversal)
拿到对端的地址信息后,Tailscale 会尝试通过 NAT 穿透来建立点对点(P2P)连接。这个过程使用了 STUN 协议,双方互相发送探测包,尝试在 NAT 路由器上打出一条直连的通道。如果双方的网络条件允许,就可以成功建立起一个 UDP 的直连隧道,数据走直连,速度快、延迟低。
受制于篇幅,我无法完整细致的讲述 NAT 穿透的原理,若对这部分感兴趣,可以阅读 Tailscale 官方的「How NAT traversal works」一文。
完整连接流程图示
自建 DERP
Tailscale 的安装在各个平台上都相对简单,官方文档已经提供了详细的操作指南。本文将不再赘述安装过程,以下内容默认你已经在相关设备上成功安装并登录了 Tailscale。
为什么要自建 DERP?
Tailscale 在全球部署了众多 DERP 2中继服务器,用于在打洞失败时接管流量中转。但由于众所周知的原因,中国大陆并没有官方部署的 DERP 节点。这意味着:
- 一旦 NAT 打洞失败,所有流量都必须绕行海外的 DERP 节点,延迟高、速度慢,体验极差;
- 某些官方 DERP 节点容易被 GFW 干扰,可能出现连接中断、握手失败等问题;
- 即使打洞成功,Tailscale 仍需通过 DERP 交换路由信息和 WireGuard 密钥,如果 DERP 不可达,连接质量也会受到影响。
因此,在国内网络环境下,自建一个本地 DERP 节点,不仅可以显著提高连接稳定性和传输性能,还能规避部分网络封锁所带来的不可预期问题,是一个非常值得做的优化。
准备工作
前面提到,DERP 是基于 HTTP 的,所以你需要准备好一个 HTTP 反代服务,并自行解决 SSL 证书的签发等基础问题。本文使用 Docker 部署,在部署开始之前,你需要在你的服务器上装好 Docker 以及 Docker Compose 等附加组件。为了编辑配置文件,你当然也得知道如何使用 nano 之类的编辑器。为了最好的效果,你的服务器最好拥有静态公网 IPv4+IPv6 双栈地址。
如果以上条件都具备,就可以开始部署了。
| |
docker-compose.yml
| |
network_mode: host是一个关键配置,表示容器将共享宿主机的网络栈。如果使用 Docker 默认的 bridge 网络模式,容器的网络会经过 Docker 内网转发,会造成 DERP 的 STUN 服务识别到 Docker 172.17.0.0/16网段下的地址,而
无法识别到客户端正确的外网地址,导致 Tailscale 客户端无法正确连接。
| |
前面提到所有通过 DERP 的数据都是端到端加密的,DERP 并不知道是谁在使用,这意味着如果不采取措施,任何知道你 DERP 服务器地址和端口号的人都可以使用它。这条配置的作用是挂载宿主机的 Tailscale 套接字文件到容器内,目的是允许 derper 服务通过 Tailscale 的 tailscaled 服务进行身份验证。配合DERP_VERIFY_CLIENTS=true,可以防止你的 DERP 节点被他人白嫖。
需要注意的是:
- 宿主机必须已经安装并登陆 Tailscale 客户端(tailscaled),否则这个文件不存在,容器会报错;
- tailscaled 必须以 root 权限运行,才能创建这个 sock 文件。
反向代理
以 Caddy 为例,需要反向代理 4433 端口,并为其部署 SSL 证书。
| |
需要注意的是,如果你和我一样使用 Caddy 配合 dnsproviders 申请泛域名证书,Tailscale 的 MagicDNS 可能会导致 Caddy 本地证书验证失败而报错,需要手动指定resolvers参数解决。
访问刚刚反代的节点,如果出现以下页面,说明配置正确。

配置 ACL 策略
打开 Tailscale 控制台的「Access Controls」页面配置 ACL 策略,将配置好的 DERP 加上。
Tailscale 的 ACL 策略是用 HuJSON3 写的,想要在 VSCode 中编辑,选择语言为「JSON with Comments(jsonc)」即可。以下是一个配置示例:
| |
Tailscale 保留RegionID中的 1-899 作为官方节点,自建节点的 RegionID 必须大于等于 900。
测试连接
配置好 ACL 并保存,Tailscale 会自动为所有客户端同步配置,稍等片刻在客户端用tailscale netcheck测试连接。
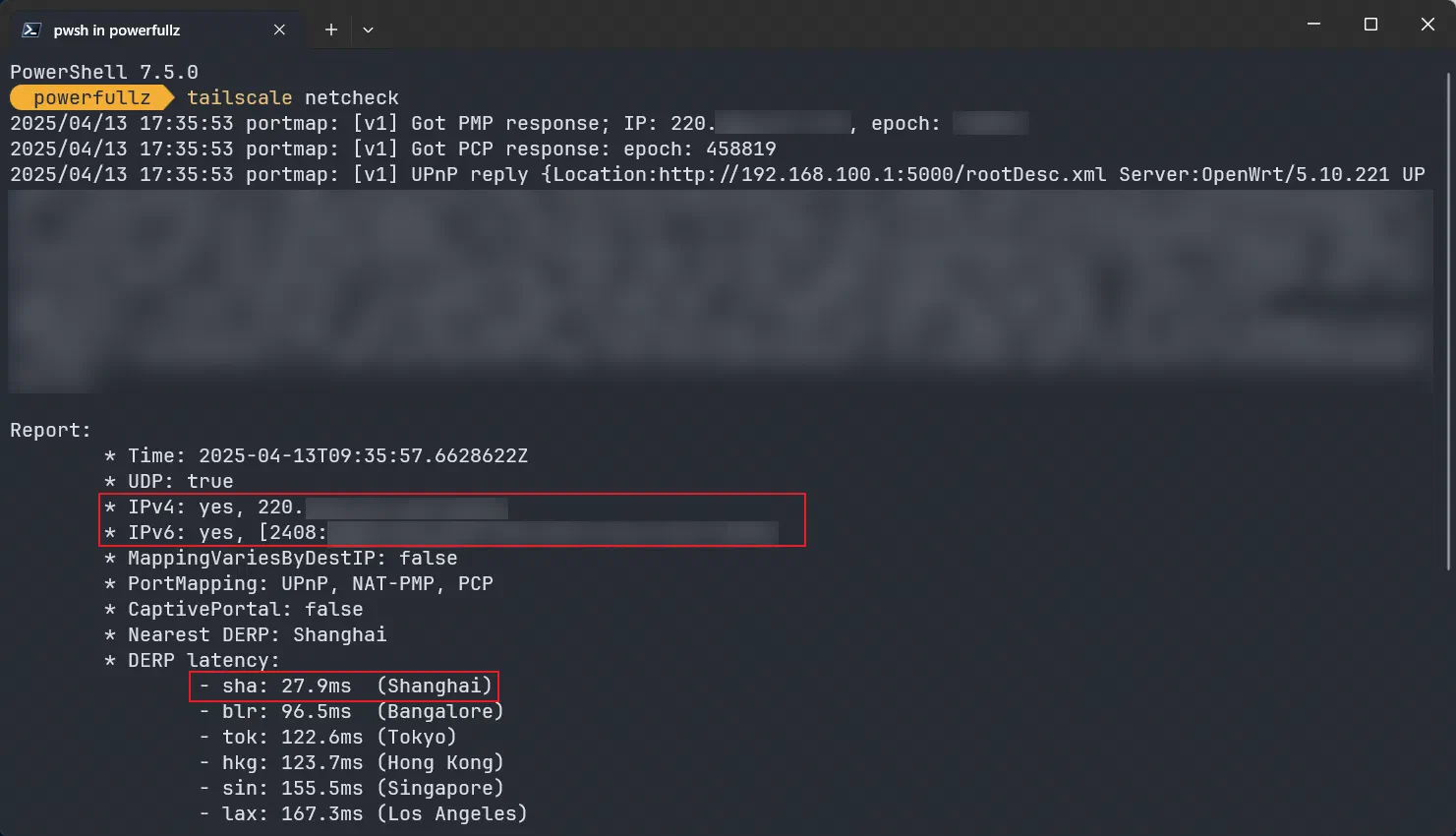
需要注意返回的 IP 是否是自己真实的公网 IP,若返回了172.17.0.0/16网段的地址,说明你 Docker 部分配置错了。
与科学上网并存:在 Exit Node 劫持流量到 Clash 内核
声明 Exit Node
在家中准备一个 24 小时开机的设备,可以是树莓派,可以是 MacMini。在上面安装 Tailscale 并将其声明为 Exit Node,并根据需要在 Tailscale 内网声明家庭内网网段,随后在控制台启用这个设备作为 Exit Node,你就获得了一个免费的 VPN,可以让你在陌生的网络环境中保持安全。
| |
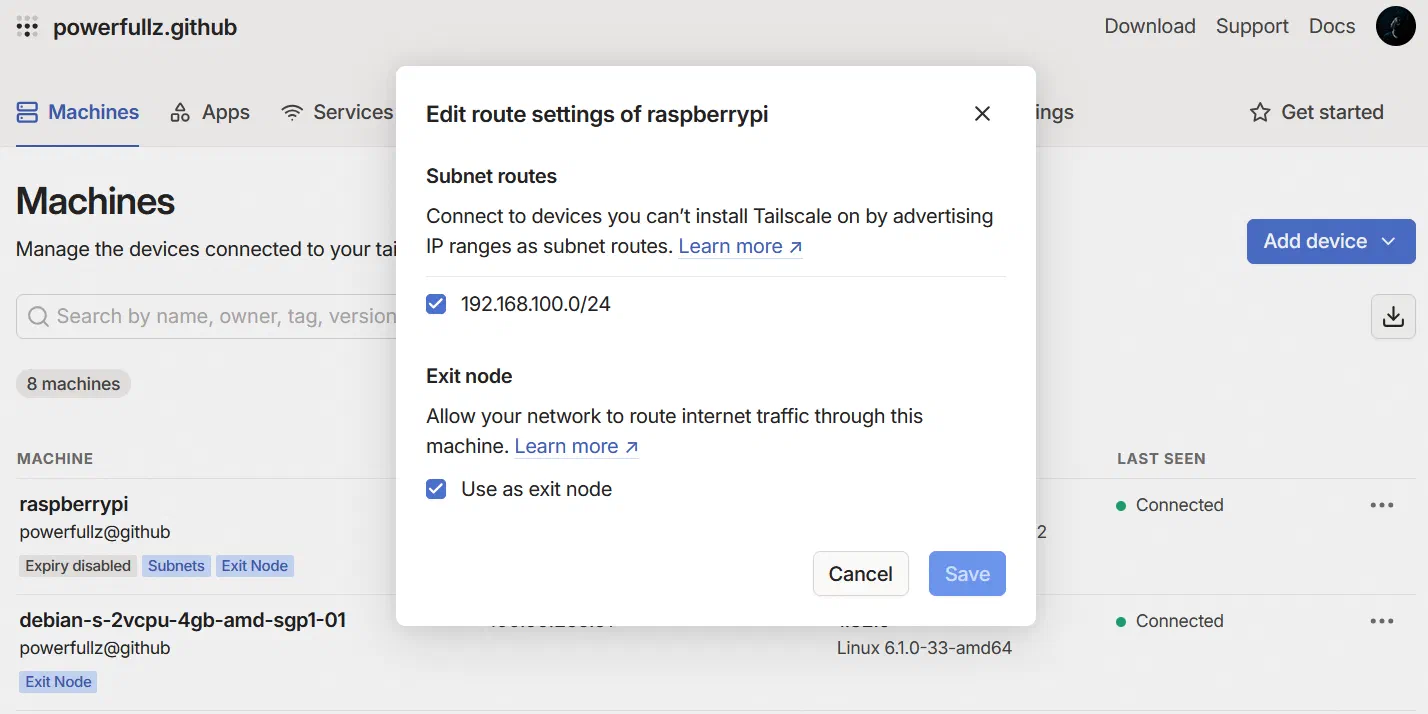
广播完成后,无论身处何地,只要能连上 Tailscale 网络,就能访问家中所有的内网设备。
启用 IP 转发和禁用 UDP GRO4
启用 IP 转发是树莓派等设备作为 Exit Node 所必须的配置,这里以树莓派为例,如果你使用其他设备,请自行查阅 Tailscale 官网教程。
| |
根据 Tailscale 官方的说法5,禁用 UDP GRO6 可以提升转发性能,但官方的持久化教程似乎在树莓派上无效,好在我们可以手动配置。
| |
针对持久化的问题手动编写 systemd 配置文件:
| |
文件内容如下:
| |
随后启动服务:
| |
在 Exit Node 劫持流量
我的 Exit Node 是一台树莓派,在树莓派上配置好 Exit Node 之后就来到了最后一步,也就是劫持手机发送到 Exit Node 上的流量,实现科学上网。出于稳定性原因,我不希望在家庭主路由上直接运行代理软件,为了实现这一点,直接在树莓派上劫持流量是唯一的选择。
首先安装 ShellCrash,请自行根据你的需要导入配置文件、配置自动任务等:
| |
随后启动服务,修改修改防火墙运行模式为纯净模式,我个人建议将 SNI 嗅探打开,并将 DNS 模式从fake-ip切换为redir-host7,同时启用 IPv6 透明代理。



设置纯净模式的目的是手动配置 iptables 以实现更精准的流量劫持。我们直接用 iptables 劫持所有 tailscale 网卡作为 Exit Node 转发的流量,首先用ifconfig查看 tailscale 网卡的名称,默认情况下一般为 Tailscale 0:
| |
劫持tailscale0网卡的所有流量到本地 Clash 内核监听端口7892,这个设置在 ShellCrash 中叫做「静态路由端口」。以及,如果你不想和我一样遇到莫名其妙的网络问题,就一定不要忘记劫持 IPv6。
| |
进阶:用 TProxy 劫持 UDP 流量
iptables 的 REDIRECT 只能重定向 TCP 流量,UDP 没有连接状态(无连接协议),所以 REDIRECT 无法保留目标地址,导致透明代理无法知道原始目标地址。
所以,如果你用如下方式劫持 UDP 流量:
| |
则这个规则不会生效或代理行为不正常。
那么,有办法代理 UDP 流量吗?有的兄弟,有的。但前提是:
- 核心支持 UDP 透明代理(Clash Premium 和 Mihomo 都支持);
- 使用 TProxy 模式,而不是 REDIRECT;
- 正确配置了 iptables mangle 表和 policy routing;
- 代理配置文件中启用了 UDP 代理(如 mode: rule + udp: true)。
假设你已经满足第一条、第二条和最后一条,则以下是一个示例8:
| |
当然,不要忘记 IPv6:
| |
路由规则持久化
ip rule和ip route创建的规则在重启后会丢失,所以需要我们手动持久化,最简单直接的方法就是创建一个脚本,并将其添加至 crontab。
创建一个脚本:
| |
编辑为如下内容:
| |
授予执行权限后编辑 Crontab:
| |
在 crontab 文件底部加上如下内容:
@reboot /usr/local/bin/policy-route.sh
原理解释:TProxy 到底是怎么转发 UDP 流量的?
如果你看到这里,也许会产生疑惑:为什么整个流程中,我们没有在 iptables 里写--to-ports,也没看到目标地址被改写,UDP 流量就莫名其妙地被代理了?这是怎么做到的?
要解释这个问题,我们先来看 TProxy 和 REDIRECT 的根本区别:
REDIRECT 模式:
- 使用 iptables nat 表;
- 将目标地址改写为本地地址(比如 127.0.0.1:7892);
- 通常用于 TCP 流量;
- 不能保留真实目标地址;
- 需要指定
--to-ports。
TPROXY 模式:
- 使用 iptables mangle 表;
- 不修改目标 IP,而是保留原始目标地址;
- 通过 fwmark 和 policy routing 将报文路由到
lo; - 代理程序监听一个特殊端口(例如 7893),并启用
IP_TRANSPARENT; - 支持 UDP 和 TCP;
- 不需要 iptables 内指定
--to-ports,因为不是 NAT,而是标记 + 路由。
TProxy 不使用 DNAT/REDIRECT,而是通过 mangle 表给数据包打上 mark,然后通过 policy routing(ip rule + ip route)将这些数据包送到 lo 接口。代理程序(如 Clash / ShellCrash)监听在 lo9 上的端口(例如 7893),通过启用 IP_TRANSPARENT 选项,可以读取数据包的原始目标 IP 和端口并进行代理转发。
简而言之,TProxy 模式只需要:
iptables给数据包打上 mark;ip rule+ip route将这些包送到lo;- 程序监听
lo上的端口并开启IP_TRANSPARENT。
所以不需要在 iptables 中指定 --to-ports,因为目标 IP 和端口保持不变,代理程序自己可以感知并处理。
iptables 规则持久化
安装iptables-persistent:
| |
安装过程中会提示你是否保存当前的 IPv4 和 IPv6 配置,选择「是」即可。之后如果你添加了新的规则,记得执行保存命令:
| |
保存后的规则文件路径:
- IPv4:
/etc/iptables/rules.v4 - IPv6:
/etc/iptables/rules.v6
你也可以直接编辑上面的rules.v4/rules.v6文件,按需修改。
最终效果
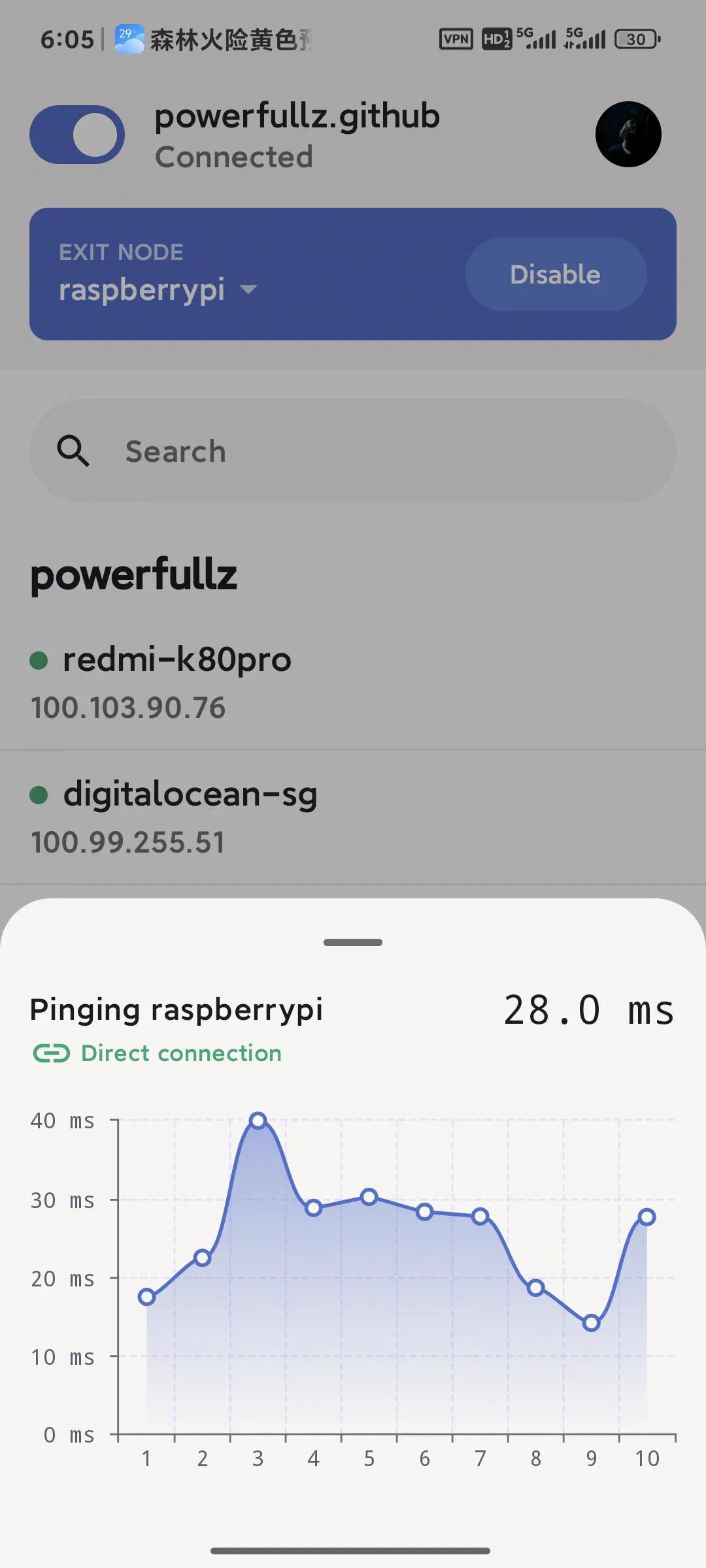
这套方案的使用体验取决于你家的上行带宽,我家的网络是下行 500M 上行 60M,目前没有遇到一次打洞失败的情况,所以基本都能跑满,延迟也尚可接受,并且可以在外地随时随地端到端加密访问家中的 Immich 和 OpenWRT 路由器等设备以及实现科学上网,总体来看,我还算比较满意。
有关 HuJSON: https://github.com/tailscale/hujson ↩︎
参考: https://tailscale.com/kb/1320/performance-best-practices#linux-optimizations-for-subnet-routers-and-exit-nodes ↩︎
UDP GRO(Generic Receive Offload)是 Linux 内核中的一种网络优化技术,主要用于合并多个小数据包以提高处理效率。但在设备作为网络转发节点的使用场景下,这可能会导致转发延迟增加和高丢包率环境下的吞吐量下降。 ↩︎
相较于
fake-ip,redir-host兼容性更好,出现问题的概率更低,也不会出现开关代理之后短时间内因为fake-ip残留而断网的情况,所以一般情况下我建议使用redir-host搭配 GeoSite 分流规则使用。我这台树莓派的 DNS 上游是已经配置好的 SmartDNS,不存在 DNS 污染的问题,体验良好。 ↩︎参考: https://blog.zonowry.com/posts/clash_iptables_tproxy/ ↩︎
lo是 Linux 系统中默认的「回环接口(Loopback Interface)」,在透明代理中,它不仅处理 localhost 流量,还被用来接收原本属于外部世界的网络连接,实现对外部流量的本地劫持和转发。 ↩︎
评论已禁用,直到您接受功能性 Cookie。