Terraform 是一款 IaC 工具,所谓 IaC 就是「基础设施即代码」,将我们的基础设施以声明式的代码写出来,随后使用terraform apply即可完成基础设施的部署,同一份配置,部署出来的一定是一模一样的基础设施(Nix OS 用户狂喜)。
传统的基础设施管理绝大部分基于人力和各种云服务商的 Dashboard,这就带来了下面这些痛点:
| 痛点 | 说明 |
|---|
| 难以重现 | 通过 Dashboard 点点点进行配置,容易改错或者改漏,而且难以复现 |
| 环境漂移 | 手动操作导致生产和测试环境配置逐渐偏离,导致极端情况下测试没问题生产直接崩 |
| 难以扩展 | 新增一套环境需要重复大量手工操作,耗时且容易出错 |
| 难以审计 | 没有变更记录,出了事不好甩锅 |
| 难以协作 | 基础设施由少数「懂的人」掌控,谁想要改都得去找这些人,效率低 |
为了解决这些问题,「基础设施即代码」的概念被提了出来,Terraform 就是其中一个著名的解决方案。
假设一个现实的使用场景,例如你每年都会购买新的 GCP 的 $300 试用金账号,虽然便宜,但是每年都要重新跑到 GCP 的面板里开机器。而有了 Terraform,想要部署同样配置的机器,只要在每次更换账号之后,将 API Token 替换成新的,随后terraform apply,只需要几分钟就能开出和你上个账号一模一样的机器、VPC、S3、防火墙配置等等。
再比如 Cloudflare DNS 和 Tunnel 的管理和迁移,也只需要将原 Tunnel 的 Ingress Rule 复制到新 Tunnel 的 Ingress Rule。即使将来要迁移到 AliDNS、Route 53 等其他服务商,我们也可以原封不动的将数据复制过去。
尤其是到了多人协作的时候,配合 Git,每次更改都有迹可循,更不需要担心合并冲突,PR 可以自动生成更改预览,出现问题可以立刻回滚到上一个版本,这些都是传统依赖人力去直接操作服务提供商 Dashboard 的做法完全无法做到的。
Terraform 是用 Go 写的,编译出来的产物自然也是单个可执行文件,所以安装起来也非常容易,Windows 下可以直接使用 Winget 安装:
1
| winget install Hashicorp.Terraform
|
如果不想使用 Winget,也可以使用 Scoop 等其他包管理器,或者将预编译的二进制文件放入$PATH,即可完成安装。
如果你在 Linux 环境下,则使用对应的包管理器安装即可,如果使用将二进制文件放入$PATH的安装方法,则要记得sudo chmod +x terraform赋予文件的执行权限。
Provider(s)
我们前面已经提到,Terraform 是一个款础设施即代码工具,作为一个工具本身,他并不绑定某个平台,而是通过 Provider(s) 与各个平台对接,要查看有哪些 Provider(s),可以浏览 Terraform 的 Registry。
状态管理
Terraform 将每次执行基础设施变更操作时的状态信息保存在一个状态文件中,默认情况下会保存在当前工作目录下的terraform.tfstate文件里,我们也可以修改配置文件自行指定其他的存储后端,例如 S3、Postgres。每次我们执行terraform apply时,Terraform 都会将目前配置文件声明的状态同现有的状态文件进行比对,从而计算变动的部分,自动确定调整顺序之后操作 Provider 落实状态变动。
现有资源的导入一直是 Terraform 为人诟病的难题,Hashi Corp. 似乎一直在坚持着一个固执且愚蠢的观点:你所有的基础设施从一开始就应当是用我们的 Terraform 创建的,所以也不存在什么资源导入的问题。
| 时间 | 版本 | 进展 | 问题 |
|---|
| 2014–2022 | v0.x–v1.4 | 只有 terraform import,一次一条,而且完全不生成配置 | 导入完还得自己手写 HCL |
| 2023.06 | v1.5 | 引入 import 块和 -generate-config-out参数,可以生成配置了 | 然而还是得一条一条写,而且还得自己提供现有资源的 ID |
| 2024.01 | v1.7 | import 块支持 for_each | 批量了,但 ID 还得自己搞 |
| 2024 下半年 | v1.12 | 引入了 terraform query 和 list 块,终于实现了自动发现资源的功能 | 然而这个功能要 Provider 要自己实现,大量 Provider 根本没跟上 |
这么多年的时间,社区一直在骂,然而,「我有一堆现有资源,怎么导入 Terraform」这个问题一直没有被认真对待。Terraform 作为「基础设施即代码」工具,设计哲学就是声明式和幂等性,Hashi Corp. 他们笃信「一切以代码声明的状态为准,就应该用 Terraform 从零开始创建资源」。但现实是绝大多数公司都有大量历史存量资源,先有资源、后有代码才是常态。这个矛盾 Hashi Corp. 承认得很晚,v1.12 的 terraform query 才算是官方第一次认真面对这个问题——但 Provider 生态的跟进嘛……真的是一言难尽。
Terraform 的文件结构很简单,其主程序运行时会无脑读取工作目录下所有的.tf文件,只要信息齐全,想给文件取什么名字都可以,比如我的文件结构就长这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| ❯ tree -a -I .git
.
├── .editorconfig
├── .github
│ ├── dependabot.yml
│ └── workflows
│ ├── terraform-apply.yml
│ ├── terraform-plan.yml
│ └── your-fork.yml
├── .gitignore
├── .terraform.lock.hcl
├── cf_dns_zones.tf
├── cf_tunnel.tf
├── dns_example_com.tf
├── dns_example_net.tf
├── dns_example_top.tf
├── dns_example_cn.tf
├── main.tf # 基础配置(terraform 块)
├── moved.tf # 移动过的资源
├── provider.tf # 每个 Provider 的配置
├── README.md
├── rename_resources.ps1
└── variables.tf # 自定义的变量
|
main.tf用于存放基础配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
| terraform {
required_providers {
cloudflare = {
source = "cloudflare/cloudflare"
version = "~> 5"
}
tencentcloud = {
source = "tencentcloudstack/tencentcloud"
version = ">= 1.81.43"
}
}
}
|
provider.tf用于存放每个 Provider 的配置:
1
2
| provider "cloudflare" {}
provider "tencentcloud" {}
|
这里留空是因为我们可以通过环境变量来传递 Credentials,而不是直接将 Credentials 写在配置文件中,例如 Cloudflare 的 Provider 就接受CLOUDFLARE_API_TOKEN作为api_token这个变量的替代。
variables.tf用于声明自定义的变量:
1
2
3
4
5
6
7
8
9
| variable "cloudflare_zone_example_com" {
description = "Cloudflare zone ID for example.com"
type = string
}
variable "cloudflare_zone_example_top" {
description = "Cloudflare zone ID for example.top"
type = string
}
|
这些变量可以通过前缀为TF_VAR_的环境变量传入,Terraform 也会自动读取terraform.tfvars文件中的变量,变量的主要用途是在别的配置文件中调用,例如:
1
2
3
4
5
6
7
8
9
10
11
12
| resource "cloudflare_dns_record" "example_cname" {
content = "${cloudflare_zero_trust_tunnel_cloudflared.Production_Tunnel.id}.cfargotunnel.com"
name = "example.example.com"
proxied = true
tags = []
ttl = 1
type = "CNAME"
zone_id = var.cloudflare_zone_id_example_com #这里调用了cloudflare_zone_example_com这个变量
settings = {
flatten_cname = false
}
}
|
有了这些基础配置,我们就可以运行terraform init初始化 Terraform 环境并锁定依赖版本,剩下的就都是我们资源的声明了。
前文提到过 Terraform 的状态管理这个概念,状态管理虽好,但在我们初始化时也带来了一个问题——在默认状态下,Terraform 的状态文件显然是空的。
此时我们需要做的是将云服务提供商上现有资源的状态导入 Terraform,这样 Terraform 才能无缝接手并管理我们的基础设施。相信大家也都看到了前文对 Terraform 资源导入问题的吐槽。以导入 Cloudflare 上托管的 DNS 记录为例,前文提到过,如果 Provider 支持,可以使用 Terraform 在 1.12 版本之后引入的terraform query,然而大多数情况下,Providers 都是没有跟进这个新功能的,Cloudflare 就属于不支持的那一类。
好在虽然 Hashi Corp. 不认真解决问题,各路高强度使用 Terraform 管理基础设施的公司就各显神通。Cloudflare 就维护了名为 cf-terraforming 的导入工具,免去了很多手动导入的麻烦。首先安装cf-terraforming,这个工具是用 Go 语言编写的,需要在有 Go 语言环境的情况下安装,或者将官方编译好的二进制文件其放入$PATH并赋予其执行权限。
1
| go install github.com/cloudflare/cf-terraforming/cmd/cf-terraforming@latest
|
这个工具的用法还是比较简单的,首先你需要以下环境变量:
1
2
3
4
5
6
7
8
9
| # 如果你使用 API Token
export CLOUDFLARE_API_TOKEN='Hzsq3Vub-7Y-hSTlAaLH3Jq_YfTUOCcgf22_Fs-j'
# 如果你使用 API Key
export CLOUDFLARE_EMAIL='user@example.com'
export CLOUDFLARE_API_KEY='1150bed3f45247b99f7db9696fffa17cbx9'
# 指定需要导入的域名的区域 ID,如果导入的是账户资源(例如 Cloudflare Tunnel)则不需要
export CLOUDFLARE_ZONE_ID='81b06ss3228f488fh84e5e993c2dc17'
|
此处的命令假设你正在使用 Bash,如果使用的是与 Bash 语法不兼容的 Shell,则需要做出调整,例如对于 Windows 上的 PowerShell,导入环境变量的语法如下:
1
| $env:CLOUDFLARE_API_TOKEN='Hzsq3Vub-7Y-hSTlAaLH3Jq_YfTUOCcgf22_Fs-j'
|
通常我们只需要设置CLOUDFLARE_API_TOKEN和CLOUDFLARE_ZONE_ID就可以了,在控制台创建 API Token 时,记得赋予这个 Token 必要的权限,本次我们只是导入 DNS 记录,所以只赋予编辑区域 DNS 的权限即可。
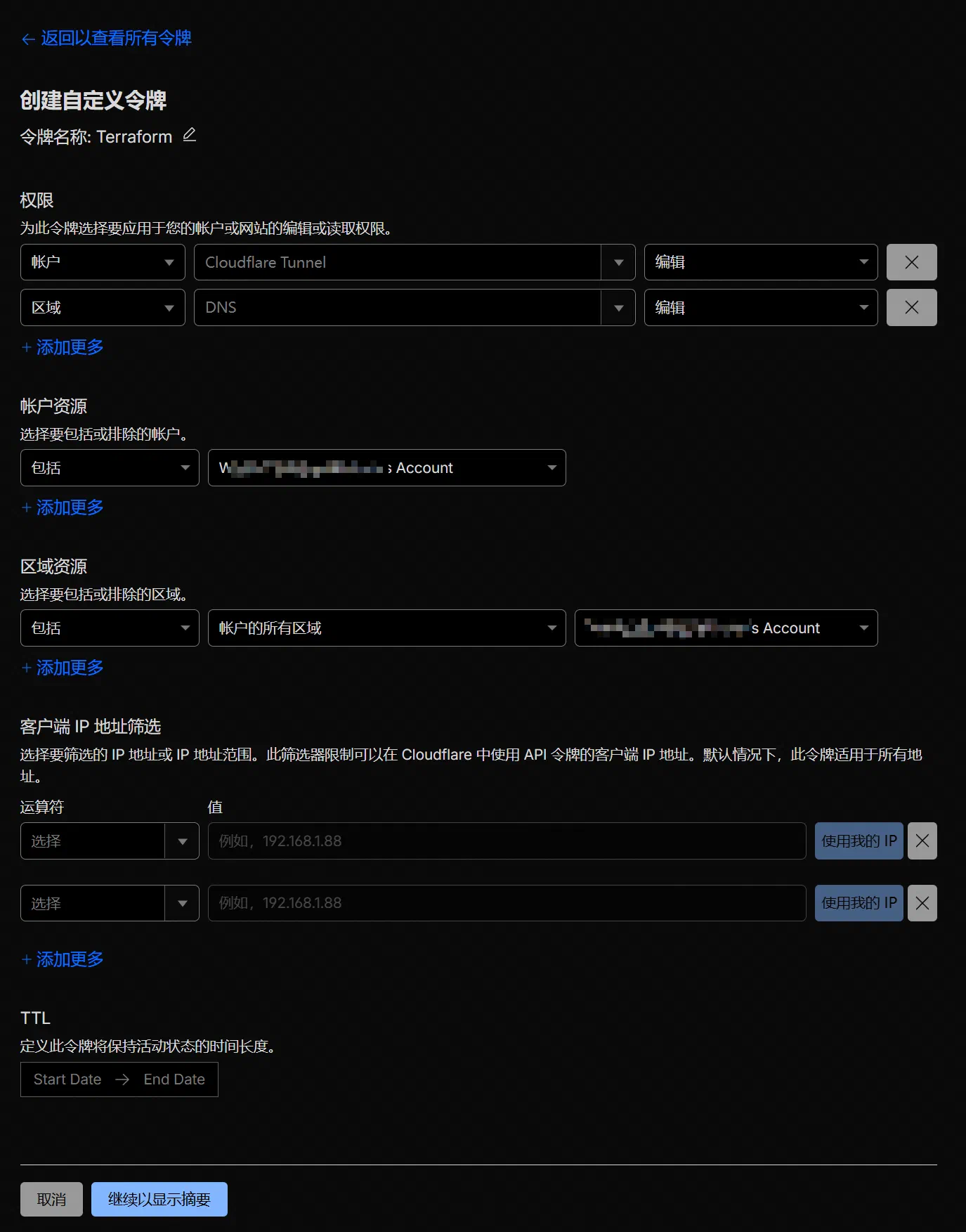
好了,准备工作全部完成,现在可以开始生成配置文件:
首先导入账户中域名的配置,也就是cloudflare_zone:
1
2
3
| cf-terraforming generate \
--key $CLOUDFLARE_API_KEY \
--resource-type "cloudflare_zone" > zone.tf
|
这一步会在当前目录下生成一个名为zone.tf的文件,里面会有如下格式的内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| resource "cloudflare_zone" "REDACTED" {
name = "REDACTED"
paused = false
type = "full"
vanity_name_servers = []
account = {
id = "REDACTED"
name = "REDACTED"
}
}
resource "cloudflare_zone" "REDACTED" {
name = "REDACTED"
paused = false
type = "full"
vanity_name_servers = []
account = {
id = "REDACTED"
name = "REDACTED"
}
}
|
现在域名资源已经导入了,但是里面的配置并没有。接下来,导入域名下的 DNS 记录:
1
2
3
4
| cf-terraforming generate \
--zone $CLOUDFLARE_ZONE_ID \
--key $CLOUDFLARE_API_KEY \
--resource-type "cloudflare_dns_record" >> dns.tf
|
这一步会在当前目录下生成一个名为dns.tf的配置文件,里面会有如下格式的内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| resource "cloudflare_dns_record" "terraform_managed_resource_5deb14xxxxxb629bf123xxxxxxxc8f_0" {
content = "67.24.33.108"
name = "example.example.com"
proxied = true
tags = []
ttl = 1
type = "A"
zone_id = "81c7f2de8dfxxxxxx52629xxxxxxfc"
settings = {}
}
resource "cloudflare_dns_record" "terraform_managed_resource_89xxxxx0bf9cxxxxxx9a_1" {
content = "35.27.108.33"
name = "terraform.example.com"
proxied = true
tags = []
ttl = 1
type = "A"
zone_id = "8xxxxxx7644e428526xxxxxx"
settings = {}
}
|
如果有多个域名需要导入,则多次分别设置环境变量CLOUDFLARE_ZONE_ID再重复运行命令即可。
这里生成的配置文件可以直接使用,也就是我们之后需要的 Terraform 配置文件。然而,此时我们仅仅只是生成了配置文件,但是目前 Terraform 的状态依然是空的,这时要是直接terraform apply,Terraform 会不管三七二十一将我们刚刚导入的声明一律视为新增资源,然后甩出一大堆「Alredy Exists」报错。所以接下来,我们需要将生成的配置文件导入 Terraform 的terraform.tfstate状态。
Terraform 在 1.5 版本引入了import块,相比以往一行一行输入命令的方式更加现代。其导入流程是先生成一个包含import块的.tf文件,下次进行terraform apply时,Terraform 就会自动为我们执行导入操作。
生成cloudflare_zone的import块:
1
2
3
4
5
| cf-terraforming import \
--resource-type "cloudflare_zone" \
--modern-import-block \
--key $CLOUDFLARE_API_KEY \
--zone $CLOUDFLARE_ZONE_ID >> import.tf
|
生成cloudflare_dns_record的import块:
1
2
3
4
5
| cf-terraforming import \
--resource-type "cloudflare_dns_record" \
--modern-import-block \
--key $CLOUDFLARE_API_KEY \
--zone $CLOUDFLARE_ZONE_ID >> import.tf
|
这一步会在当前目录下生成import.tf,它包含了所需要的导入信息,作用就是告诉 Terraform 上一步生成的每个resource块到底对应的是哪一个云服务提供商的资源 ID。这个 ID 是云服务提供商内部标记资源的代码,平常是不会在控制面板上显示的,只有在用 API 特别请求时才会知道。Terraform 在导入过程中需要用到这个 ID 以确认本地的定义对应的云端资源,以实现严格的幂等性。
好了,现在我们运行terraform plan:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| $ terraform plan
cloudflare_dns_record.minio_a: Refreshing state... [id=xxxxxxxxxxx53]
cloudflare_zero_trust_tunnel_cloudflared_config.raspberrypi: Refreshing state...
......
Terraform will perform the following actions:
# cloudflare_dns_record.terraform_managed_resource_0 will be imported
resource "cloudflare_dns_record" "terraform_managed_resource_REDACTED_0" {
content = "67.24.33.108"
created_on = "2026-04-08T10:18:12Z"
id = "5deb14c21xxxxxxx20f1c8f"
meta = jsonencode({})
modified_on = "2026-04-08T10:18:12Z"
name = "example.example.com"
proxiable = true
proxied = true
settings = {}
tags = []
ttl = 1
type = "A"
zone_id = "REDACTED"
}
# cloudflare_dns_record.terraform_managed_resource_1 will be imported
resource "cloudflare_dns_record" "terraform_managed_resource_89c149exxxxxxxxxxxba13xxxxxa_1" {
content = "35.27.108.33"
created_on = "2026-04-08T10:17:54Z"
id = "89cxxxxxxxxxxxxxxxxxx09a"
meta = jsonencode({})
modified_on = "2026-04-08T10:17:54Z"
name = "terraform.example.com"
proxiable = true
proxied = true
settings = {}
tags = []
ttl = 1
type = "A"
zone_id = "81xxxxxxxxxxxxxxxxxxxxxfc"
}
Plan: 2 to import, 0 to add, 0 to change, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────
Note: You didn't use the -out option to save this plan, so Terraform can't guarantee to take exactly
these actions if you run "terraform apply" now.
|
如果需要 Add、Change 和 Destroy 的资源数量都是 0,说明我们的导入操作没有问题,直接terraform apply --auto-approve,资源就导入完成了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| $ terraform apply --auto-approve
cloudflare_dns_record.push_a: Refreshing state... [id=REDACTED]
Terraform will perform the following actions:
# cloudflare_dns_record.terraform_managed_resource_REDACTED_0 will be imported
resource "cloudflare_dns_record" "terraform_managed_resource_REDACTED_0" {
content = "67.24.33.108"
created_on = "2026-04-08T10:18:12Z"
id = "REDACTED"
meta = jsonencode({})
modified_on = "2026-04-08T10:18:12Z"
name = "example.example.com"
proxiable = true
proxied = true
settings = {}
tags = []
ttl = 1
type = "A"
zone_id = "REDACTED"
}
# cloudflare_dns_record.terraform_managed_resource_REDACTED_1 will be imported
resource "cloudflare_dns_record" "terraform_managed_resource_REDACTED_1" {
content = "35.27.108.33"
created_on = "2026-04-08T10:17:54Z"
id = "REDACTED"
meta = jsonencode({})
modified_on = "2026-04-08T10:17:54Z"
name = "terraform.example.com"
proxiable = true
proxied = true
settings = {}
tags = []
ttl = 1
type = "A"
zone_id = "REDACTED"
}
Plan: 2 to import, 0 to add, 0 to change, 0 to destroy.
cloudflare_dns_record.terraform_managed_resource_REDACTED_1: Importing... [id=REDACTED/REDACTED]
cloudflare_dns_record.terraform_managed_resource_REDACTED_1: Import complete [id=REDACTED/REDACTED]
cloudflare_dns_record.terraform_managed_resource_REDACTED_0: Importing... [id=REDACTED/REDACTED]
cloudflare_dns_record.terraform_managed_resource_REDACTED_0: Import complete [id=REDACTED/REDACTED]
Apply complete! Resources: 2 imported, 0 added, 0 changed, 0 destroyed.
|
状态存储和持续集成
IaC 的核心价值之一就在于可以轻易实现基于 Git 的多人协作,以及 CI 的持续集成,但是在此之前,又有一个新的问题需要解决——terraform.tfstate到底放哪里:没人想要换一次环境辛辛苦苦导入的状态就丢一次。
Terraform 目前支持以下几种保存状态的后端:
- local
- remote
- azurerm
- consul
- cos
- gcs
- http
- Kubernetes
- oci
- oss
- pg
- s3
没有特殊需求可以像我一样选择s3,毕竟 Cloudflare R2 有免费额度,不用白不用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| terraform {
backend "s3" {
bucket = "terraform"
key = "terraform.tfstate"
region = "auto"
endpoints = {
s3 = "https://REDACTED.r2.cloudflarestorage.com"
}
# R2 不需要这些 AWS 的验证
skip_credentials_validation = true
skip_metadata_api_check = true
skip_region_validation = true
skip_requesting_account_id = true
use_path_style = true
}
}
|
对于 S3 的后端,建议用AWS_ACCESS_KEY_ID和AWS_SECRET_ACCESS_KEY两个环境变量来存储 Credentials:
1
2
| export AWS_ACCESS_KEY_ID='REDACTED'
export AWS_SECRET_ACCESS_KEY='REDACTED'
|
配置完成,运行terraform init -migrate-state,配置就成功存储到云上了,以后不论在何处修改配置、运行terraform apply都无须担心 Terraform 的 State 不同步的问题。
接下来就是 Github CI 的配置,其实很简单,无非就是每次git push时触发一次terraform init、terraform fmt和terraform apply,以下是我的.github/workflows/apply.yml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| name: "Terraform Apply"
on:
push:
branches:
- main
env:
TF_IN_AUTOMATION: "true"
CLOUDFLARE_API_TOKEN: "${{ secrets.CLOUDFLARE_API_TOKEN }}"
AWS_ACCESS_KEY_ID: "${{ secrets.AWS_ACCESS_KEY_ID }}"
AWS_SECRET_ACCESS_KEY: "${{ secrets.AWS_SECRET_ACCESS_KEY }}"
TF_VAR_cloudflare_zone_id_example_com: "${{ vars.TF_VAR_CLOUDFLARE_ZONE_ID_EXAMPLE_COM }}"
TF_VAR_cloudflare_zone_id_example_top: ${{ vars.TF_VAR_CLOUDFLARE_ZONE_ID_EXAMPLE_TOP }}
jobs:
terraform:
name: "Terraform Apply"
runs-on: ubuntu-latest
permissions:
contents: read
concurrency:
group: terraform-apply
cancel-in-progress: false
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Setup Terraform
uses: hashicorp/setup-terraform@v4
- name: Terraform Init
run: terraform init -input=false
- name: Terraform Apply
run: terraform apply -input=false -auto-approve
|
对于 PR 则应当让 CI 自动为每次 PR 附上terraform plan的输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
| name: Terraform Plan
on:
pull_request:
paths:
- "**/*.tf"
- ".github/workflows/terraform-plan.yml"
permissions:
contents: read
pull-requests: write
env:
TF_IN_AUTOMATION: "true"
CLOUDFLARE_API_TOKEN: ${{ secrets.CLOUDFLARE_API_TOKEN }}
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
TF_VAR_cloudflare_zone_id_example_com: "${{ vars.TF_VAR_CLOUDFLARE_ZONE_ID_EXAMPLE_COM }}"
TF_VAR_cloudflare_zone_id_example_top: ${{ vars.TF_VAR_CLOUDFLARE_ZONE_ID_EXAMPLE_TOP }}
jobs:
plan:
name: Terraform Plan
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
- uses: hashicorp/setup-terraform@v4
- name: Terraform fmt
id: fmt
run: terraform fmt -check -recursive
continue-on-error: true
- name: Terraform Init
id: init
run: terraform init -input=false
- name: Terraform Validate
id: validate
run: terraform validate -no-color
- name: Terraform Plan
id: plan
run: terraform plan -input=false -no-color
continue-on-error: true
- name: Post Plan to PR
uses: actions/github-script@v8
with:
github-token: ${{ secrets.GITHUB_TOKEN }}
script: |
const { data: comments } = await github.rest.issues.listComments({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.issue.number,
});
const botComment = comments.find(c =>
c.user.type === 'Bot' && c.body.includes('<!-- terraform-plan -->')
);
const planOutput = `${{ steps.plan.outputs.stdout }}`.substring(0, 65000);
const body = `<!-- terraform-plan -->
#### Terraform Plan
| Step | Result |
| -------- | --------------------------------- |
| fmt | \`${{ steps.fmt.outcome }}\` |
| init | \`${{ steps.init.outcome }}\` |
| validate | \`${{ steps.validate.outcome }}\` |
| plan | \`${{ steps.plan.outcome }}\` |
<details><summary>展开 Plan 详情</summary>
\`\`\`terraform
${planOutput}
\`\`\`
</details>`;
if (botComment) {
await github.rest.issues.updateComment({
owner: context.repo.owner,
repo: context.repo.repo,
comment_id: botComment.id,
body
});
} else {
await github.rest.issues.createComment({
issue_number: context.issue.number,
owner: context.repo.owner,
repo: context.repo.repo,
body
});
}
- name: Fail if plan failed
if: steps.plan.outcome == 'failure'
run: exit 1
|
后续的工作流程
到这一步,Terraform 的「接管初始化」已经结束了,后面就进入了日常维护阶段。这个阶段其实就三件事:
- 创建新资源
- 修改现有的资源
- 删除不再需要的资源
常用的操作就两个:terraform plan和terraform apply,如果是个人使用,小的改动直接提交就算了;如果是团队协作,每次修改则应当遵循能 PR 就不直接 Commit 的原则。
创建基础设施
假设你现在要新增一条 DNS 记录,或者新建一个 Tunnel、一个对象存储桶,流程如下:
flowchart TD
C1[新建分支
如 feat/add-minio-record] --> C2[新增 resource 块]
C2 --> C3[terraform fmt + validate]
C3 --> C4[terraform plan]
C4 --> C5{仅新增预期资源?}
C5 -- 否 --> C6[修正配置后重跑 plan]
C6 --> C4
C5 -- 是 --> C7[提交 PR]
C7 --> C8[合并后 CI apply]最理想的plan输出是:
X to add0 to change0 to destroy
如果你只是想加东西,结果出现了to destroy,那就先别冲动,通常是引用写错、变量搞错,或者不小心改了资源地址,仔细检查是什么地方出了问题。
修改与删除基础设施
修改流程和创建类似,但要多一步——评估变更是否会触发重建。
因为很多 Provider 字段是ForceNew,你以为只是改个字段,Terraform 看完说:「好的,删了重建。」这在我们修改 DNS 的这个场景并不是什么很大的问题,但是到了云实例这种资源,如果删除重建势必会造成损失。
建议按下面这个顺序来:
flowchart TD
M1[修改 .tf] --> M2[terraform plan]
M2 --> M3{出现 replace/destroy?}
M3 -- 否 --> M7[确认影响范围]
M7 --> M8[terraform apply]
M3 -- 是 --> M4[暂停并复核变更]
M4 --> M5[必要时加 lifecycle 保护]
M5 --> M6[安排变更窗口]
M6 --> M8对生产环境来说,创建、修改得慢一点并不是什么很大的问题,最应当看重的是操作的正确性,慢一点,不要出错。IaC 不是比手速,IaC 比的是可预期性。
如果是删除资源(比如下线某个 DNS 记录、清理废弃 Tunnel),走下面这个流程:
flowchart TD
D1[确认资源已废弃检查业务/监控/脚本依赖] --> D2[删除 resource 块或调整 count/for_each]
D2 --> D3[terraform plan]
D3 --> D4{to destroy 是否符合预期?}
D4 -- 否 --> D5[回滚修改并继续排查依赖]
D5 --> D1
D4 -- 是 --> D6[准备回滚方案并选低峰窗口]
D6 --> D7[PR 审核通过]
D7 --> D8[terraform apply]
D8 --> D9[删除资源后的可用性检查]日常协作建议
- 把 Credentials 放环境变量或 CI Secret,别写进
.tf和仓库 - 对关键资源开启保护策略,防止误删
- 将目录按资源类型拆分
- 定期执行
terraform plan做基础设施漂移检查和校正,避免在面板误操作手动修改
虽然这套流程看起来很麻烦,但每一次变更都有记录、可审计、可回滚,最重要的是可复现,这才是 IaC 最有价值的地方。
参考

评论已禁用,直到您接受功能性 Cookie。