Stable Diffusion 是去年就出來的東西了,我沒有去早點玩這個東西是因為當時我的電腦算力真的不夠,我直接用 Mid Journey 的 Discord 羣組湊合體驗了一下,換了新電腦自然要玩玩這個東西。
部署
我直接部署stable-diffusion-web-ui,畢竟這已經是一個成熟的方案了。
Clone 倉庫
| |
修改webui-user.bat:
| |
我用的 RTX 3060 Laptop 有6G視訊記憶體,所以選用--medvram引數。
執行用戶,注意這套指令碼要使用普通用戶(非管理員)執行。
| |
這套東西只在 Python 3.10.6 上測試過,當時用 Python 3.11 時安裝過程出現了報錯,如果現在用的是 Python 3.11 記得換成 Python 3.10.6,修改環境變數,然後重啓電腦。
DiffusionWrapper has 859.52M params
正常情況下,這套指令碼會自動下載所需要的依賴。記得我當時在部署的時候是半夜,掛着終端代理,這個指令碼跑了半天。第二天起來,依然卡在昨天晚上的地方,也就是DiffusionWrapper has 859.52M params。
上課回來,在網上一搜尋,才發現遇到這個問題的人還真不少,Github 上也有人在stable-diffusion-webui的官方庫裏提了 issue,看起來是hugging-face的file-download.py出現了bug,而非stable-diffusion-webui本身的問題。這是解決方案:Github上的解決方案。
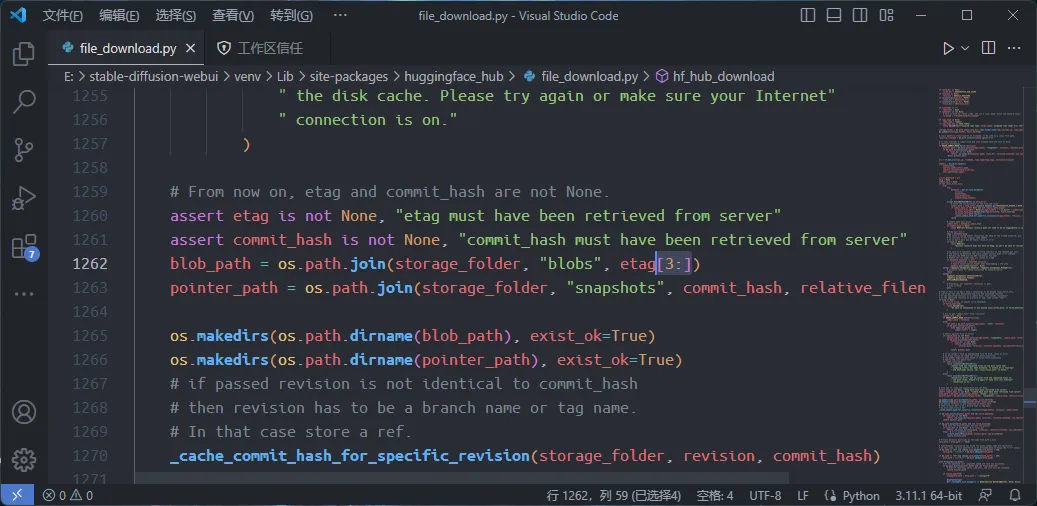
定位到<INSTALL_FOLDER>\stable-diffusion-webui\venv\Lib\site-packages\huggingface_hub\file_download.py的 1262 行,將其修改為:
| |
重新執行webui-user.bat,這次 webui 順利啓動了。
stable-diffusion-webui跑在本地預設的埠號是7860,訪問http://localhost:7860就可以看到這套 Web UI 了。
找模型
部署工作至此已告一段落,但stable-diffusion-webui部署下來自帶的模型生成的圖片並不符合我的需求和口味,我相信大部分人也不會只用這個預設的模型,那麼隨後的一件事就是找模型。
去哪找?
起初我也不知道去哪找,於是就傻乎乎的 Google 了一下:stable diffusion anime model。別説,還真奏效了。搜出來的結果裏立刻就出現了Hugging face和Civit-AI。Civit-AI還能直觀的看到每個模型的預覽圖。
除此之外,Reddit 等論壇上,像我一樣的個人部落格上,都可以看到網友們的模型推薦,用這種方式找模型也很不錯。
Problem solved.
找到的模型
就這麼去了 Civit-AI 的首頁,第一眼就被counterfeit模型吸引了。
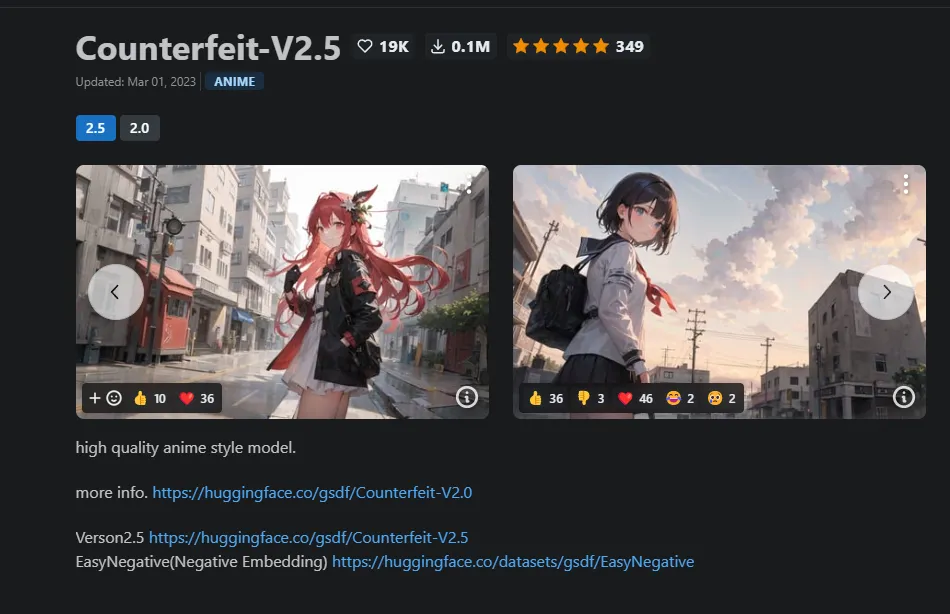
除此之外,Anything也是非常流行的模型,也被我收入囊中。
可以自己訓練模型嗎?
先説結論:理論上來説,可以。但我這個 3060 Laptop……還是算了吧。
Stable diffusion 有幾種主要的訓練方法,Textual Inversion, Hyper Network, Dream booth, Lora。即使是配置要求最低的 Lora,也要求至少 8G 的視訊記憶體,而 3060 Laptop 只有 6G 視訊記憶體。既然如此,就不折磨自己了,還是直接用訓練好的現成模型吧,感謝社羣。
開始用
一開始我在 CivitAI 上下載下來Counterfeit-V2.5模型,CivitAI 上只有一個 4.1G 的CounterfeitV25_25.safetensors檔案。我將其下載下來丟進了<INSTALL DIR>\stable-diffusion-webui\models\Stable-diffusion資料夾,重新整理一下Web UI的模型列表就看到了這個模型,於是我就很順利的載入了這個模型開始用了。
這……不對啊
先來看看這個時候的生成效果:



這……不對啊。怎麼感覺我被這個模型的樣圖給騙了?
來看看作者生成的樣圖:


我們用的真的是同一個模型嗎?可以看到我和作者生成了一張大體十分相似的圖片,那是我用和作者相同的 Prompt 和種子生成的,作者生成的圖片,不論是畫面細節,還是色彩,都和我一開始用這個模型的時候生成的幾乎完全不是一個東西,難道我是下錯模型了?
找問題
我在論壇裏翻找遇到相同問題的帖子,發現其實遇到同樣問題的人還真不少,大多數人都抱怨生成的圖片細節不夠,色彩不夠鮮豔。根據我的經驗,肯定是少裝了些什麼東西。
EasyNegative
EasyNegative 可以被看做一個 Super Prompt,用於改善模型生成圖片的質量。

谷歌 EasyNegative 第一個出來的就是為counterfeit-v2.5模型設計,於是我便下載下來使用了。連結附上:gsdf EasyNegative
This is a Negative Embedding trained with Counterfeit. Please use it in the “\stable-diffusion-webui\embeddings” folder. It can be used with other models, but the effectiveness is not certain.
這套 EasyNegative 同樣適用於 AbyssOrangeMix2,anything等模型,我願稱之為必備。
到了這一步,我總算是知道為什麼所有人的 Prompt 裏總要有個EasyNegative了,原來是個 Super Prompt。
裝好 Easy Negative,生成的圖片就正常多了。

但總感覺色彩還是不好看啊……是不是還缺了什麼?
VAE
我在 Hugging Face 上看了一下,這裏模型作者提供了遠遠不止一個的檔案。
VAE 的全程是 Variational Autoencoder。旨在幫助用戶更好的渲染影象,其中也包括了色彩的部分。而不知出於什麼原因,作者只在 Hugging Face 上提供了他的 VAE。
裝好 VAE,再次生成影象,這下的影象終於完全正常了。

這幾天生成的圖片
這是我挑選的一些圖片




陰間的圖片
其實上面最後一張圖的手指已經是有生成問題的,而生成的圖片裏還有更陰間的圖片。



玩玩外掛
這套 WebUI 還有外掛可玩,這幾天又心血來潮玩玩比較出名的外掛。
至於怎麼安裝外掛,都是在這套 Web UI 的 Extensions 裏。一是從官方倉庫里拉取外掛列表,二是自己找到外掛的倉庫連結拉庫下載即可。
我們來玩玩外掛。
controlnet
controlnet 可以透過草圖控制畫中人物的姿勢,理論上可以解決上面生成的人物陰間的問題。
評論已停用,直到您接受功能性 Cookie。